A step-by-step guide to deploying an MLFlow server using GitHub Actions and Cloud Run
If you work professionally as a Data Scientist or a Machine Learning Engineer, you probably have reached a point where it is crucial to manage and track experiments, models, and workflows efficiently. It’s no longer practical to write model hyperparameters and metrics on paper or in an Excel sheet. We’ve all been there, and it’s okay. But it’s time to improve.
There are a few good platforms for experiment tracking available. My favourite is MLFlow, an open-source platform for managing the end-to-end machine learning lifecycle. Recently I was presented with a challenge: securely deploy an MLFlow server to enable the team of Data Scientists to access and share information internally using Google Cloud Platform. I couldn’t find many comprehensive guides on this process, so after suffering for a few days, I’ve decided to share an easy-to-follow guide so you can upload yours in minutes! Even if you’re not using GCP, the steps can be easily adapted to other cloud services.
Let’s begin!
1) Prerequisite:
This tutorial assumes you have Google Cloud CLI installed on your machine. If you don’t have it yet, follow the documentation here.
All of the steps involving Google Cloud can be performed manually using the console, I’m using the CLI just for quickness.
2) Defining the Architecture:
There are a few scenarios to record runs and artifacts using MLFlow, from local files, to a SQLAlchemy database, or remotely to a tracking server. In this guide, we are using MLflow Tracking Server enabled with proxied artifact storage access.
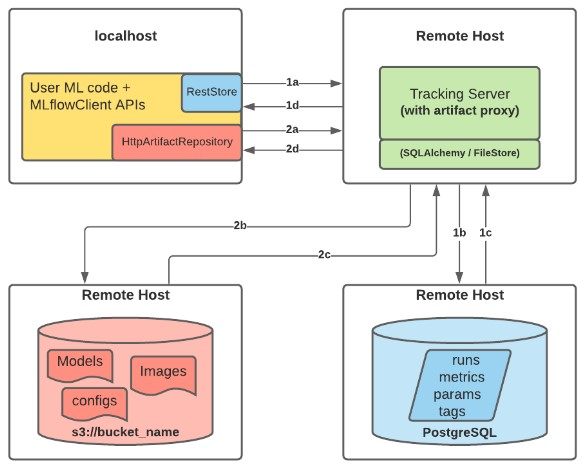
The benefit of this configuration is that it allows the tracking server to manage the operation of loading and saving artifacts, documents, and files without the need for end users to access the server’s storage, which would involve the management of sensible credentials. All your co-workers need is the tracking server URI, and they are good to go.
3) Setting up Google Cloud Platform:
Begin by signing into your Google Cloud account with the command:
gcloud init
Follow the prompts to log into your Google account and set up the project you will be working on as your default project. You will be prompted with a list of all open projects to select, and an option to create a new one. I like to open a new project, just to keep easier to manage.
Make sure that billing is enabled for your project.
There are a few important resources we need, let’s go through each of them individually.
3.1) Database:
MLFlow uses a database to store experiment data, so we’re going to launch a PostgreSQL instance. Use the following command:
gcloud sql instances create INSTANCE_NAME \
--database-version=POSTGRES_15 \
--region=us-central1 \
--tier=db-f1-micro \
--storage-type=HDD \
--storage-size=10GB \
--authorized-networks=0.0.0.0/0
Replace INSTANCE-NAME with a name of your choice.
The configurations can be selected according to each need (I chose the cheapest), but for this tutorial, we need to give special attention to Authorized Networks.
Ideally, you want your databases to have Private IPs, especially if you’re working in a company environment. That requires setting up a VPC Network to access those bases, which isn’t quite the objective here. Therefore, for now, we will keep Public IP for our database.
We are adding 0.0.0.0/0 as authorized network, which gives access to the database from any IP address on the internet. Again, this is supposed to be a straight-to-the-point tutorial, and it’s not meant to be a production environment yet.
Now we need to create a user with access to this instance, so run the command:
gcloud sql users create USERNAME \
--instance=INSTANCE-NAME \
--password=PASSWORD
Create your own custom name and password for the user.
The next step is to create the database itself. Run the following command:
gcloud sql databases create DATABASE-NAME --instance=INSTANCE-NAME
3.2) Bucket:
Now we’re going to create a bucket using Cloud Storage to use it as our remote artifact repository for MLFlow. Create a new bucket with the command:
gcloud alpha storage buckets create gs://BUCKET-NAME \
--enable-hierarchical-namespace \
--uniform-bucket-level
Inside this bucket, we need to create a folder called “mlruns”:
gcloud alpha storage folders create --recursive gs://BUCKET-NAME/mlruns/
3.3) Container Repository:
We need a place to store the containers for Cloud Run, so we are going to open a new repository on Artifact Registry:
gcloud artifacts repositories create REPO-NAME \
--location=us-central1 \
--repository-format=docker
3.4) Service Account:
For our application to be able to access Cloud SQL, Cloud Storage, and Cloud Run, we need to pass the required permissions provided by Google Cloud. For that, we need to create a Service Account:
gcloud iam service-accounts create SA-NAME
We are going to give our new service account a bunch of roles. Google Cloud doesn’t allow binding multiple roles at once, so we have to do them individually. The general command is this:
gcloud projects add-iam-policy-binding PROJECT_ID --member='serviceAccount:SA-NAME@PROJECT_ID.iam.gserviceaccount.com' --role='ROLE_NAME'
Use the same code, just replace PROJECT_ID, the service account you just created, and the role flag for each permission:
- Cloud SQL Editor:
--role='roles/cloudsql.editor'
- Storage Object Admin:
--role='roles/storage.objectAdmin'
- Secret Manager Secret Accessor:
--role='roles/secretmanager.secretAccessor'
Artifact Registry Administrator:
--role='roles/artifactregistry.admin'
Cloud Functions Admin:
--role='roles/cloudfunctions.admin'
Cloud Deploy Service Agent:
--role='roles/clouddeploy.serviceAgent'
To get your PROJECT_ID to run the command correctly, use this:
gcloud config get-value project
Alternatively, you can try this to list the service accounts linked to your project, including the one we just created:
gcloud iam service-accounts list
The last thing we need to do is enable Cloud Run API in your project if it’s not enabled yet:
gcloud services enable run.googleapis.com
3.5) Secrets:
Now that our service account has all the necessary roles, we need to download access keys that we’ll configure as a secret using Secret Manager. This is very sensitive information that should not be available to everyone, even in a company environment!
First, let’s obtain the access keys as a JSON file:
gcloud iam service-accounts keys create sa-private-key.json --iam-account=SA-NAME@PROJECT_ID.iam.gserviceaccount.com
This will create a JSON file called “sa-private-key.json” with the credentials. Again, be extra careful with this file, it will be deleted as soon as the information is safely stored.
Now we are creating a secret variable called access_keys with the contents of sa-private-key.json, which will be used by our container later.
gcloud secrets create access_keys --data-file=sa-private-key.json
If you are doing the steps manually, open Secret Manager and create a new secret called “access_keys” with the content of sa-private-key.json, just copy and paste.
Now we are going to add the PostgreSQL database URL and the cloud storage bucket URL as secrets, you don’t want that open in your repositories, even if they are private. Use these commands, just change the placeholders with your information:
gcloud secrets create database_url
echo -n "postgresql://<USERNAME>:<PASSWORD>@<IP>/<DATABASE-NAME>" | \
gcloud secrets versions add database_url --data-file=-
gcloud secrets create bucket_url
echo -n "gs://BUCKET-NAME/mlruns" | \
gcloud secrets versions add bucket_url --data-file=-
The names database_url and bucket_url are not placeholders, they are referenced exactly like this in the GitHub Actions workflow later, so don’t change them.
The database IP can retrieved with the command:
gcloud sql instances describe INSTANCE-NAME
Or by opening Cloud SQL on your console.
That is it for GCP at the moment. Don’t delete the credentials yet, we still need to use them on GitHub Actions.
4) GitHub Repository:
To simplify this guide, I created this repository containing the basic structure you need to run the first version of this project so you don’t have to copy all the files. Feel free to fork it and open it on your local machine.
This is the structure:
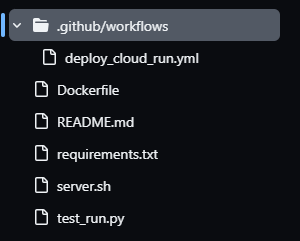
Let’s go through what you need to do:
4.1) GitHub Secret:
Open the repository settings and go to Secrets -> Actions under the “Security” tab.

Create a new repository secret called GOOGLE_APPLICATION_CREDENTIALS, and copy and paste the contents of sa-private-key.json there.
After this, you can safely delete this file from your local machine. This will be used by GitHub Workflows to authenticate with Google Cloud later.
4.2) Dockerfile:
FROM python:3.9-buster
WORKDIR /
COPY requirements.txt requirements.txt
COPY server.sh server.sh
ENV GOOGLE_APPLICATION_CREDENTIALS='./secrets/credentials'
RUN pip install --upgrade pip && pip install -r requirements.txt
EXPOSE 8080
RUN chmod +x server.sh
ENTRYPOINT ["./server.sh"]
The Dockerfile is very simple, we are defining the access_keys secret as an environmental variable, which will be passed as a mounted volume ‘secrets/credentials/’ when we deploy the container to Cloud Run, then we install the requirements, expose port 8080, and define the entry point, which is a bash script that runs the following command:
#!/bin/bash
mlflow db upgrade $POSTGRESQL_URL
mlflow server \
--host 0.0.0.0 \
--port 8080 \
--backend-store-uri $POSTGRESQL_URL \
--artifacts-destination $STORAGE_URL
POSTGRESQL_URI and STORAGE_URL are passed as GCP secrets when we deploy the container to Cloud Run.
4.3) YML file:
This file is the workflow used by GitHub Actions to build our container and deploy it on Cloud Run.
# Docker build and push container to Artifact Registry, deploy on Cloud Run
name: Deploy MLFlow Server
on:
push:
branches: [main]
jobs:
login-build-push:
name: Build, Push and Run
runs-on: ubuntu-latest
env:
REGION: MY_REGION # edit here
PROJECT_ID: MY_PROJECT_ID # edit here
REPOSITORY: MY_ARTIFACT_REPOSITORY # edit here
SERVICE_ACCOUNT: MY_SERVICE_ACCOUNT # edit here
SERVICE_NAME: MY_SERVICE_NAME # edit here
steps:
- name: Checkout
uses: actions/checkout@v3
- id: 'auth'
name: Authenticate to Google Cloud
uses: google-github-actions/auth@v1
with:
project_id: '${{ env.PROJECT_ID }}'
credentials_json: '${{ secrets.GOOGLE_APPLICATION_CREDENTIALS }}'
- name: 'Docker config'
run: |-
gcloud auth configure-docker ${{ env.REGION }}-docker.pkg.dev
- name: 'Build container'
run: |-
docker build -t "${{ env.REGION }}-docker.pkg.dev/${{ env.PROJECT_ID }}/${{ env.REPOSITORY }}/mlflow:${{ github.sha }}" .
- name: 'Push container'
run: |-
docker push "${{ env.REGION }}-docker.pkg.dev/${{ env.PROJECT_ID }}/${{ env.REPOSITORY }}/mlflow:${{ github.sha }}"
- name: Deploy Google Cloud Run
run: |
gcloud run deploy "${{ env.SERVICE_NAME }}" \
--image "${{ env.REGION }}-docker.pkg.dev/${{ env.PROJECT_ID }}/${{ env.REPOSITORY }}/mlflow:${{ github.sha }}" \
--region "${{ env.REGION }}" \
--service-account "${{ env.SERVICE_ACCOUNT }}" \
--update-secrets=/secrets/credentials=access_keys:latest \
--update-secrets=POSTGRESQL_URL=database_url:latest \
--update-secrets=STORAGE_URL=bucket_url:latest \
--memory 2Gi \
--allow-unauthenticated \
--port 8080
The only thing you need to do here is to replace the variables inside “env” with the ones you have created so far in this project.
- REGION: The region you are using (example: us-central1)
- PROJECT_ID: Your project ID from GCP
- REPOSITORY: Your repository created on Artifact Registry
- SERVICE_ACCOUNT: The full e-mail of the service account
- SERVICE_NAME: An appropriate name for your Cloud Run service
This file uses the secret GOOGLE_APPLICATION_CREDENTIALS we just defined to authenticate with Google Cloud, builds the container based on the Dockerfile code, pushes the container to Artifact Registry, and deploys on Cloud Run.
All you have to do is push your changes to the main branch, which will trigger GitHub Actions to perform all these steps, and by the end of it, you should have your server up and running effortlessly!
5) Results:
After pushing our changes to the main branch, GitHub Actions will trigger our job, and we can see that it went all the way to the end without errors.
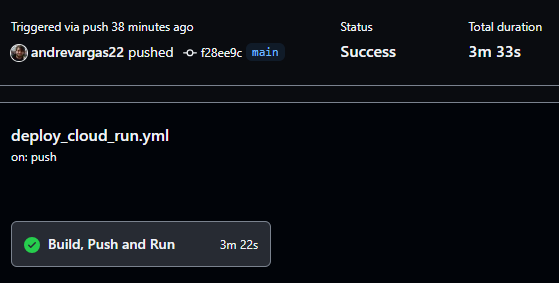

Open Google Cloud console and go to Cloud Run, you should be able to see your recently created service:
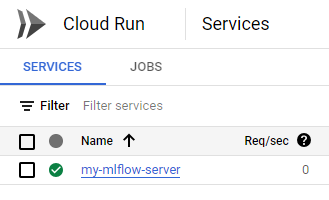
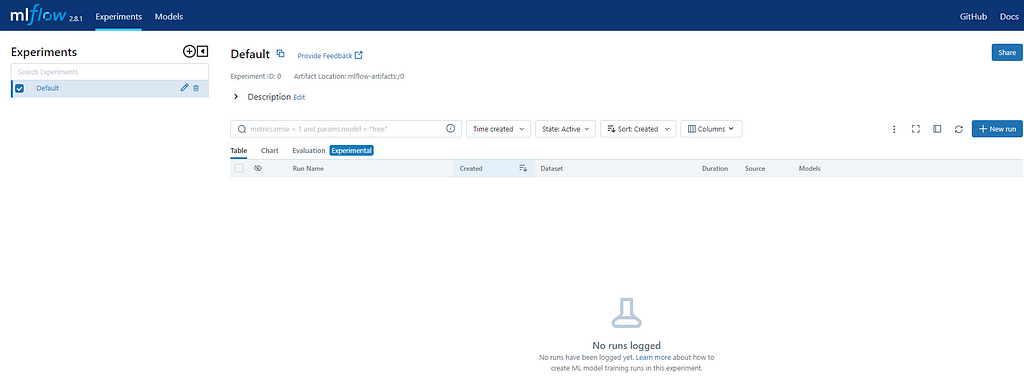
Open it, and click on the link provided by Google Cloud. If everything went according to the plan, you should be able to see the MLFlow UI!
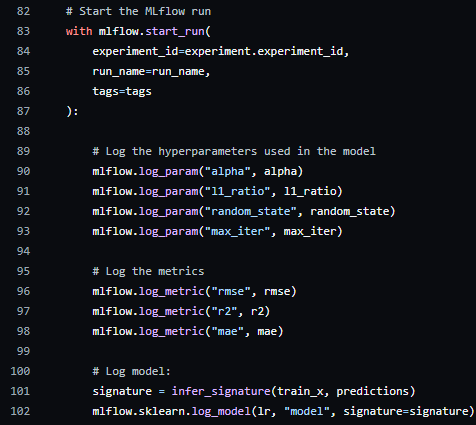
Now it’s time to test it, in the provided repository there is a file called “test_run.py”, a Python script that runs an experiment on MLFlow. The only variable you need to change is TRACKING_URI:

Replace it with the link provided by Google Cloud to your application. At the end of the script, an experiment run is logged into MLFlow, with its hyperparameters, metrics, and the model itself as an artifact:
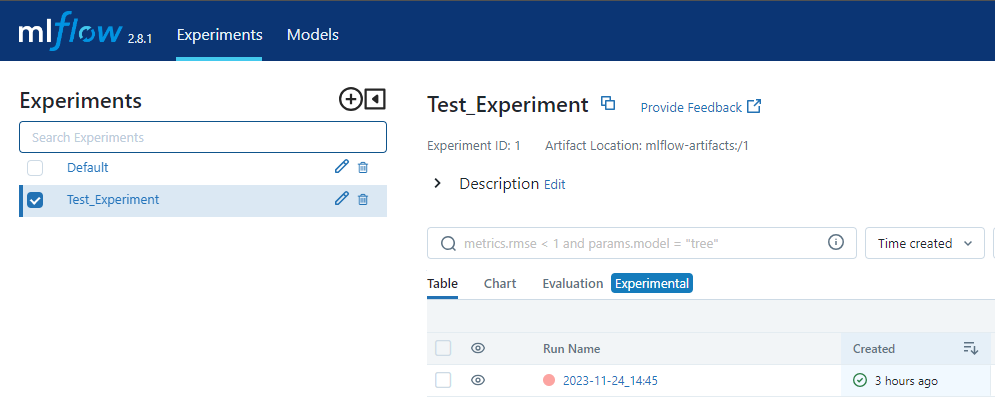
If we look at our server after running the code, it has registered our experiment:
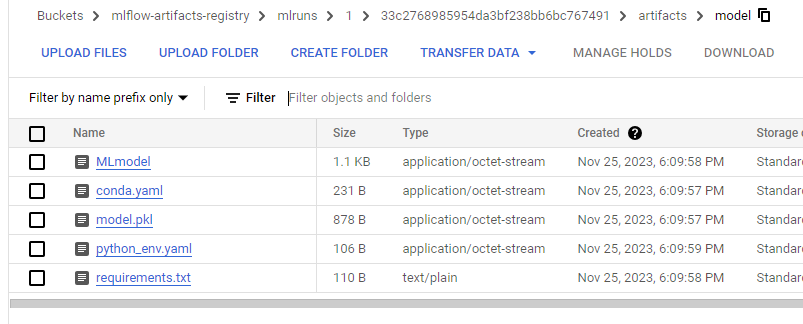
And if we open our bucket in Cloud Storage, we can see the model artifacts inside the experiment folder, as they should be:
Congratulations! You successfully launched an MLFlow Server with Continuous Deployment using Google Cloud Platform and GitHub Actions! If you want to update your server, all you need to do is push to the main branch, and in a few minutes, your new server will be up and running!
And since we are using a remote PostgreSQL database and a GCP bucket to store our artifacts, we don’t need to worry about losing any data. Once a new container is up, the data will be the same.
6) Improvements before production:
If you want to use this in a production environment, there are a few steps not covered here that you should consider first:
- Remember that our database has public IPs, you might want to change them to private IPs for safety. For that, you have to set up a VPC network peering connection between the server and the network where the PostgreSQL instance is located.
- Since everyone with your tracking server URI can log an experiment, you should consider using IAP (Identity-Aware Proxy) to take care of authentication and authorization, that way you can restrict access to your app, making it safer. Biju Kunjummen has a nice article describing this process.
- Alternatively, upon the release of version 2.5.0, MLFlow added a new built-in authentication feature. Implementing it could be another way to restrict access to your application. You can read the docs here.
- Consider having another YML file to deploy a server in the development phase. If you want to try a new feature or change something, you don’t want to risk your server breaking in production.
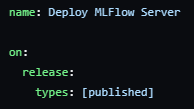
- Consider switching the workflow trigger from a push to the main branch to a release publication. This way, you can consolidate all your testing and deployment tasks into a single workflow execution, rather than running a new container every time there’s a push to the main branch. After you’ve tested everything in development, simply push your changes to the main branch and create a new release, which will automatically trigger the GitHub Actions workflow. This change in your code will do that:
If you have any questions or problems with this guide, hit me up and I’ll do my best to help!